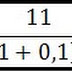Basicamente, quando estimamos um modelo econométrico, alguns problemas típicos surgem. Entre tais problemas há os velhos conhecidos, como a heteroscedasticidade, a autocorrelação dos resíduos ou a multicolinearidade. Esses problemas podem afetar sua análise e viesar seu modelo, e há formas de combatê-los. Mas hoje, aqui, trataremos de outra forma de problema não muito rara na econometria, as variáveis que apresentam modificação em seu comportamento sob determinadas circunstâncias qualitativas.
Por exemplo, o caso clássico de diferenças de salários entre homens e mulheres, explicada por aspectos culturais subjetivos; Numa estimativa dos aspectos que definam um salário, o modelo precisa levar em conta se está tratando de homem ou mulher na sua previsão, pois este aspecto qualitativo influencia a capacidade de estimação. Um outro exemplo poderia ser a quantidade de turistas que desembarcam no Brasil todos os anos, e observar a quebra estrutural que deverá haver nas épocas da Copa do Mundo e das Olimpíadas que ocorrerão no país; Essas variáveis qualitativas precisam ser consideradas em especial.
Mas como trabalhar com essas condições especiais? Basicamente, a isto se dedica esse texto.
ANÁLISE DA BASE DE DADOS
Basicamente, o que será feito é num primeiro momento é analisar a sua base de dados para se observar se há de fato variáveis qualitativas ali. Essas variáveis são diferentes de outras como "renda" ou "taxa de juros", exatamente pelo aspecto dessas últimas serem medidas em números. Na análise da sua base de dados você ainda averiguará se houve vieses instrumentais na coleta dos dados ou na metodologia de escolha e separação das variáveis. Se a sua pesquisa incluir ainda números-índices, há ainda aspectos problemáticos específicos a esses a se considerar.
O que faremos quando encontramos as variáveis qualitativa, é atribuir-lhas valores numéricos para que elas se tornem então passivas de mensuração, através de um artifício de construção de variáveis binárias ou dummies.
.................................................................................................
Exemplo:
Digamos que temos um modelo que explique a nota do ENADE de um aluno segundo os seguintes aspectos:
Nota(t) = B0 + B1(anograd (t)) + B2(mednot(t)) + erro
Onde, "nota" é a nota do aluno no ENADE de um determinado ano "t", "anograd" é a o ano (série ou período) que o aluno cursa no seu curso e "mednot" é a media de suas notas ao longo do seu curso ("erro" é a variável estocástica). Falta alguma variável aí? Alguns poderão alertar que há diferenças entre um aluno da universidade pública e um aluno da universidade privada. Bom, podemos propor então uma variável dummie aqui. Podemos separar as faculdades em pública ou particular.
Temos assim que o modelo para a contar com um novo elemento:
Nota(t) = B0 + B1(anograd(t)) + B2(mednot(t)) + B(3)(1 p/ publica e 0 p/privada) + erro
Agora, o parâmetro B(3) só apresentará seu valor se o aluno pesquisado for da universidade pública, e será ignorada se o aluno for da universidade privada. Observe então que na verdade, temos um valor que acrescentará ao intercepto. Podemos até testar se há realmente diferença entre os alunos das universidades públicas e privadas se "B0 + B3" (intercepto do aluno da rede pública) for diferente de "B0" (intercepto do aluno da rede privada), esse mesmo teste pode ainda ser feito analisando-se a significância do parâmetro B3 pelo teste t.
Você esperaria que esses valores fossem iguais ou diferentes?
Observe também que para duas características distintas nós só incluímos uma variável, e nesse caso haveria multicolinearidade perfeita, um problema que viesaria a estimativa. De fato, só precisamos de uma, dado que a existência de uma é condicionada à inexistência da outra. No entanto, se não tivéssemos o intercepto B0, as duas características até poderiam ser incluídas no modelo sem problemas, e teríamos que separar um coeficiente B para cada qual (no caso teríamos B3 e B4),
Nota(t) = B1(anograd(t)) + B2(mednot(t)) + B3(publ) + B4(privd) + erro
e ainda poderíamos separar um modelo para cada qual:
NotaPublica(t) = B1(anograd(t)) + B2(mednot(t)) + B(3)+ erro
NotaPrivada(t) = B1(anograd(t)) + B2(mednot(t)) + B(3) + erro
Nesse caso, os coeficientes B(3) e B(4) incluiriam o valor absoluto do intercepto para cada categoria, e não mais a diferença em relação à outra categoria. Note que se o intercepto não for incluído na equação, em geral é desejável incluir ambas as variáveis dummies na regressão. De fato, se deixarmos de incluir a dummy referente a uma das categorias, estaremos implicitamente supondo que o intercepto dessa categoria é zero. Se excluíssemos "publ" da equação sem regressão estaríamos supondo que o intercepto para um aluno de uma faculdade pública é zero.
É claro que podemos tomar mais de uma dummie para um determinado modelo para quando houverem mais de uma características qualitativa a ser considerada. Se por exemplo, além da diferença entre a natureza pública e privada da universidade do sujeito quisermos tomas também a diferença entre a natureza pública ou privada da sua escola no ensino médio, poderíamos acrescentar uma nova dummie, digamos, "publsg" e "partsg" para tal característica.
.................................................................................................
No exemplo anterior supusemos que há um efeito do aspecto qualitativo sobre o intercepto, mas podemos também supor que a diferenças qualitativa entre elementos da amostra podem gerar inclinações diferentes para alguma das variáveis explicativas. Bem, alguns poderão alertar que as notas possuem dificuldades diferentes de serem obtidas entre uma universidade e outra¹. Por exemplo, conseguir um "6" na USP deve ser muito mais difícil do que conseguir um "10" na Uniban. Nesse caso, podemos adotar um procedimento que é o de incluir no modelo um regressor adicional, correspondente à multiplicação de uma das duas dummies (“publ”, digamos)
pela variável “mednot”:
Nota(t) = B0 + B1(anograd(t)) + B2(mednot(t)) + B(3)(publ) + B4("publ""mednot") + erro
Lógicamente, a mesma argumentação poderia se estender para o ano de graduação, já que hoje se observa ser muito mais fácil passar de série nas privadas do que nas públicas:
Nota(t) = B0 + B1(anograd(t)) + B2(mednot(t)) + B(3)(publ) + B4("publ""mednot") + B5("publ"anograd) + erro
Observe que isso é o mesmo que estimar duas equações diferentes, uma para os alunos da universidade pública e outra para os alunos da rede privada.
Como ja fora abordado antes, todo esse procedimento nos permite testar a hipótese de que não há diferença entre os alunos da rede pública e privada (H0), contra a hipótese de que haja tal diferença (H1). Nesse caso, a hipótese nula seria:
H0: B3 = B4 = B5 = 0
Que constitui-se num teste de significância conjunta dos parâmetros, que pode ser realizado através do teste F ou do teste t para cada qual. O teste de Chow² talvez fosse o mais apropriado, já que estamos tratando de um sistema com restrições em seus elementos (estimaríamos os modelos restrito e irrestrito e compararíamos os ajustes em cada caso). Em outros termos, estaríamos testando se os coeficientes são constantes para toda a amostra.
¹. Alguns podem ainda acusar o modelo de possuir multicolinearidade, mas isso é assuntos para outro texto. Por aqui, é importante saber que essa possível colinearidade entre ano de graduação e media das notas pode ser ignoradas, ja que não há uma correspondência exata entre as duas coisas, afinal um aluno pode passar para outra fase com diversas notas, tanto acima quanto abaixo da média (as famosas notas de exame).
². Também conhecido como teste de mudança estrutural.